ASST1: Synchronization
This assignment is available online at
https://www.ops-class.org/asst/1/.
The online version is easier to read and includes helpful links, embedded video
walkthroughs, and other useful resources.
|
1. Introduction
In this assignment you will implement new synchronization primitives for OS/161 and use them to solve several synchronization problems.
Once you complete ASST1 you should have a fairly solid grasp of the pitfalls of concurrent programming and—more importantly—how to avoid those pitfalls in the code you write during the rest of the semester.
To complete this assignment you will need to be familiar with the OS/161 thread code. The thread system provides interrupts, control functions, spinlocks, and semaphores. You will implement locks, condition variables, and reader/writer locks.
1.1. Objectives
After completing ASST1 you should:
-
Understand the OS/161 thread subsystem and existing synchronization primitives: spinlocks and semaphores.
-
Have implemented working locks, condition variables, and reader-writer locks that you can use it later assignments.
-
Be able to properly address different synchronization problems by choosing and applying the correct synchronization primitive.
1.2. Collaboration Guidelines
ASST1 is your first chance to write real kernel code. Here are the guidelines for how to work with other students and work with your partner (if you have one):
| Pair programming to complete the implementation tasks is strongly encouraged. |
| Answering the code reading questions side-by-side with your partner is strongly encouraged. |
| Helping other students with Git, GDB, editing, and with other parts of the OS/161 toolchain is encouraged. |
| Discussing the code reading questions and browsing the source tree with other students is encouraged. |
| Dividing the code reading questions and development tasks between partners is discouraged. |
| Copying any answers from anyone who is not your partner or anywhere else and submitting them as your own is cheating. |
| You may not refer to or incorporate any external sources without explicit permission 1. |
2. Writing Readable and Maintainable Code
Whenever you program you should aim to write well-documented, readable code.
If you are working alone, you will appreciate this yourself. If you are working with others, they will appreciate it. If you are publishing code to the broader community, others will both appreciate and be impressed by it.
These assignments provide you with a chance to continue developing good code writing habits. If you are working with a partner, good style will help them understand your code and you understand theirs. It will also help the course staff understand your code when you need help. And you are starting with a very well-formatted and commented code base which provides an excellent example of what to do.
There is no single right way to organize and document your code. It is not our intent to dictate a particular coding style for this class. The best way to learn about writing readable code is to read other people’s code. Read the OS/161 code, read your partner’s code, read the source code of some freely available operating system. When you read someone else’s code, note what you like and what you don’t like. Pay close attention to the lines of comments which most clearly and efficiently explain what is going on. When you write code yourself, keep these observations in mind.
2.1. Comments Are Not a Panacea
Note that commenting, while potentially useful, does not make up for poor coding conventions. In many cases, well-structured code with good choices of variables and function names needs comments only in cases where something unusual must be pointed out.
For example, try to determine what the following (intentionally obfuscated) code on the left does. The click on the right side for the much better solution. Note that with appropriately named variables no commentary is needed for this very familiar piece of code.
struct a {
char *b;
struct foo *c;
};
static struct a *d = NULL;
void e() {
struct a *f = d;
struct a *g;
d = NULL;
while (f != NULL) {
g = f->c;
f->c = d;
d = f;
f = g;
}
}struct item {
char *data;
struct foo *next;
};
static struct item *list = NULL;
void reverse_list() {
struct item *current = list;
struct item *next;
list = NULL;
while (current != NULL) {
next = current->next;
current->next = list;
list = current;
current = next;
}
}2.2. Just a Few Tips
Here are some general tips for writing better code:
-
Group related items together, whether they are variable declarations, lines of code, or functions.
-
Use descriptive names for variables and procedures. Be consistent with this throughout the program.
-
Comments should describe the programmer’s intent, not the actual mechanics of the code. A comment which says "Find a free disk block" is much more informative than one that says "Find first non-zero element of array." The first adds information to what is present in code itself, the second does not.
-
Avoid repetition. Cut and pasting code is generally an extremely bad idea. Refactor things instead.
-
Keep functions short. Short functions are more likely to be reusable as well as comprehensible. Good function names describe exactly what the function does and make it easy for others to use your interface.
-
Use assertions. Assertions are a great way to help proactively debug your code. When assertions fail it can indicate either that some part of your code is not working properly, or that your assumptions about what would be true at that point are incorrect. Both are great things to find out.
You and your partner will probably find it useful to agree on a coding style.
For instance, you might want to agree on how variables and functions will be
named (my_function, myFunction, MyFunction, mYfUnCtIoN, or
ymayUnctionFay) since your code will have to interoperate and be jointly
readable. Note that OS/161 uses the my_function convention, so you may want
to too.
3. Setup

We have provided a framework allowing you to develop and test your solutions for the ASST1 synchronization problems described below.
This framework consists of:
-
kern/synchprobs/*: these files are where you will implement your solutions to the synchronization problems. -
kern/test/synchprobs.c: this file contains driver code we will use to test your solutions. You can and should change this file to stress test your code, but there should be no dependencies between your synchronization problem solutions and the problem drivers. We will replace the contents of this file (and the rest of thekern/testdirectory) during testing.
To include these files in your kernel you will need enable the synchprobs
OS/161 kernel configuration option when you configure your kernel to start
ASST1. Once you do this you should notice two new menu options under the
tests menu.
Finally, to successfully run the ASST1 tests you will need to configure your kernel to use a large amount of memory. We suggest the maximum of 16 MB. This is because your kernel currently leaks memory allocations that are larger than a page, and that includes all 4K thread stacks. So you will find that even if you correctly allocate and deallocate memory in your synchronization primitives and problems, your kernel will only run a certain number of tests before it runs out of memory and `panic`s. This is normal. However, you should make sure that your kernel does not leak smaller amounts of memory. Your kernel includes tools to help you measure this.
4. Concurrency in OS/161
The goal of synchronization is to eliminate any undesirable timing effects—or race conditions—on the output of your programs while preserving as much concurrency as possible.
For the synchronization problems we provide, threads may run in different orders depending on the order of events, but by using the synchronization primitives you will build, you should be able to guarantee that they meet the constraints inherent to each problem (while not deadlocking).
4.1. Built-In Tests
When you boot OS/161 you should see options to run various thread tests. The
thread test code uses the semaphore synchronization primitive. You should
trace the execution of one of these thread tests in GDB to see how the
scheduler acts, how threads are created, and what exactly happens in a
context switch. You should be able to step through a call to thread_switch
and see exactly where the current thread changes.
Thread test 1—or tt1 at the kernel menu or on the command line—prints the
numbers 0 through 7 each time each thread loops. Thread test 2 (tt2) prints
only when each thread starts and exits. The latter is intended to show that
the scheduler doesn’t cause starvation—the threads should all start
together, spin for awhile, and then end together. It’s a good idea to
familiarize yourself with the other thread tests as well.
4.2. Debugging Concurrent Programs
One of the frustrations of debugging concurrent programs is that timing
effects will cause them them to do something different each time. The end
result should not be different—that would be a race condition. But the
ordering of threads and how they are scheduled may change. Our test drivers
in the kern/test directory will frequently have threads spin or yield
unpredictably when starting tests to create more randomness. However, for
the purposes of testing you may want to create more determinism.
The random number generator used by OS/161 is seeded by the random device
provided by System/161. This means that you can reproduce a specific
execution sequence by using a fixed seed for the random device. You can pass
an explicit seed into random device by editing the random line in your
sys161.conf file. This may be help you create more reproducible behavior,
at least when you are running the exact same series of tests.
4.3. Code Reading Questions
While these code reading questions are ungraded, it is strongly recommended that you complete them with you partner.
4.3.1. Thread questions
-
What happens to a thread when it calls
thread_exit? What about when it sleeps? -
What function—or functions—handle(s) a context switch?
-
What does it mean for a thread to be in each of the possible thread states?
-
What does it mean to turn interrupts off? How is this accomplished? Why is it important to turn off interrupts in the thread subsystem code?
-
What happens when a thread wakes up another thread? How does a sleeping thread get to run again?
5. Implementing Synchronization Primitives
It’s finally time to write some OS/161 code. The moment you’ve been waiting for!
It is possible to implement the primitives below on top of other primitives—but it is not necessarily a good idea. You should definitely read and understanding the existing semaphore implementation since that can be used as a model for several of the other primitives we ask you to implement below.
5.1. Implement Locks
Implement locks for OS/161. The interface for the lock structure is defined
in kern/include/synch.h. Stub code is provided in kern/threads/synch.c.
When you are done you should repeatedly pass the provided lt{1,2,3} lock tests.
Note that you will not be able to run any of these tests an unlimited number
of times. Due to limitations in the current virtual memory system used by
your kernel, appropriately called dumbvm, your kernel is leaking a lot of
memory. However, your synchronization primitives themselves should not leak
memory, and you can inspect the kernel heap stats to ensure that they do
not. (We will.)
You may wonder why, if the kernel is leaking memory, the kernel heap stats
don’t change between runs of sy1, for example, indicating that the
semaphore implementation allocates and frees memory properly. The reason is
that the kernel malloc implementation we have provided is not broken, and
it will correctly allocate, free and reallocate small items inside of the
memory made available to it by the kernel. What does leak are larger
allocations like, for example, the 4K thread kernel stacks, and it is these
large items that eventually cause the kernel to run out of memory and
panic. Look at kern/arch/mips/vm/dumbvm.c for more details about what’s
broken and why.
5.2. Implement Condition Variables
Implement condition variables with Mesa—or non-blocking—semantics for
OS/161. The interface for the condition variable structure is also defined in
synch.h and stub code is provided in synch.c.
We have not discussed the differences between condition variable
semantics. Two different varieties exist: Hoare, or blocking, and Mesa,
or non-blocking. The difference is in how cv_signal is
handled:
-
In Hoare semantics, the thread that calls
cv_signalwill block until the signaled thread (if any) runs and releases the lock. -
In Mesa semantics the thread that calls
cv_signalwill awaken one thread waiting on the condition variable but will not block.
Please implement Mesa semantics. When you are done you should repeatedly
pass the provided cvt{1,2,3,4} condition variable tests.
5.3. Implement Reader-Writer Locks
Implement reader-writer locks for OS/161. A reader-writer lock is a lock that threads can acquire in one of two ways: read mode or write mode. Read mode does not conflict with read mode, but read mode conflicts with write mode and write mode conflicts with write mode. The result is that many threads can acquire the lock in read mode, or one thread can acquire the lock in write mode.
Your solution must also ensure that no thread waits to acquire the lock
indefinitely, called starvation. Your implementation must solve many
readers, one writer problem and ensure that no writers are starved even in
the presence of many readers. Build something you will be comfortable using
later. Implement your interface in synch.h and your code in synch.c,
conforming to the interface that we have provided.
Unlike locks and condition variables, where we have provided you with a test
suite, we are leaving it to you to develop a test that exercises your
reader-writer locks. You will want to edit kern/main/menu.c to allow
yourself to run your test as rwt1 from the kernel menu or command line. We
have our own reader-writer test that we will use to test and grade your
implementation.
Does this depart from our normal practice of providing you with the tools necessary to evaluate your assignment? Yes. And for a very good reason: writing tests is a critical development practice. You will write a lot of OS/161 code this semester, and particularly for ASST2 and ASST3 our tests are designed to tell if everything is working at a very high level. They are comprehensive tests, not unit tests, which target a particular piece of functionality. Writing good unit tests is extremely important to building large pieces of software—some even claim that you should write the unit test first and then the implementation that passes it. So we are using this opportunity to force you to write a unit test in the hopes that you will continue this practice later.
6. Solving Synchronization Problems
The following problems will give you the opportunity to solve some fairly straightforward synchronization problems.
We have provided you with basic driver code in kern/tests/synchprobs.c that
starts a predefined number of threads which call functions in
{whalemating.c,stoplight.c}. You are responsible for
implementing those functions which determine what those threads do. You
can—and should—make changes to the driver code in synchprobs.c, but note
that this file will be replaced by the drivers we cook up for testing. Also
note that that code is not the same as what we have provided you.
When you configure your kernel for ASST1, the driver code and extra menu
options for executing your solutions are automatically compiled in. Type ?
at the menu to get a list of commands. Remember to specify a seed to use in
the random number generator by editing your sys161.conf file. It is much
easier to debug initial problems when the sequence of execution and context
switches is reproducible.
There are two synchronization problems posed for you. You can solve these problems using any mixture of semaphores, locks, condition variables, and reader-writer locks. However, one way may be more straightforward than another and so you should put some thought into choosing the correct primitives.
6.1. The Classic CS161 Whale Mating Problem
You have been hired by the New England Aquarium’s research division to help find a way to increase the whale population. Because there are not enough of them, the whales are having synchronization problems in finding a mate. The trick is that in order to have children, three whales are needed; one male, one female, and one to play matchmaker—literally, to push the other two whales together 2.
Your job is to write the three procedures male(), female(), and
matchmaker(). Each whale is represented by a separate thread. A male whale
calls male(), which waits until there is a waiting female and matchmaker;
similarly, a female whale must wait until a male whale and matchmaker are
present. Once all three are present, the magic happens and then all three
return.
Each whale thread should call the appropriate
{male,female,matchmaker}_start() function when it begins mating or
matchmaking and the appropriate {male,female,matchmaker}_end() function
when mating or matchmaking completes. These functions are part of the problem
driver in synchprobs.c and you are welcome to change them, but again we
will install and use our own versions for testing. We have provided stub code
for the whale mating problem that you should use in whalemating.c.
The test driver in synchprobs.c forks thirty threads, and has ten of them
invoke male(), ten of them invoke female(), and ten of them invoke
matchmaker(). Stub routines, which do nothing but call the appropriate
_start() and _end() functions, are provided for these three functions.
Your job will be to re-implement these functions so that they solve the
synchronization problem described above.
When you are finished, you should be able to examine the output from running
sp1 and convince yourself that your solution satisfies the constraints
outlined above.
6.2. The Buffalo Intersection Problem
If you drive in Buffalo you know two things very well:
-
Four-way stops are common.
-
Knowledge of how to correctly proceed through a four-way stop is rare.
In general, four-way stops are so tricky that they’ve even been known to flummox the otherwise unflummoxable Google self-driving car, which both knows and is programmed to follow the rules.
Given that robot cars are the future anyway, we can rethink the entire idea of a four-way stop. Let’s model the intersection as shown below. We consider the intersection as composed of four quadrants, numbered 0–3. Cars approach the intersection from one of four directions, also numbered 0–3. Note that we have numbered the quadrants so that a car approaching from direction X enters the intersection in quadrant X.
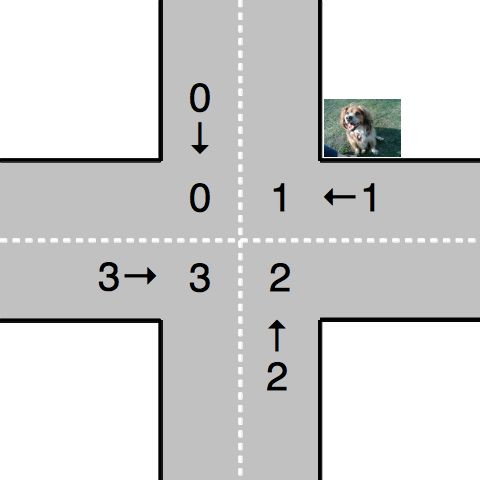
Given our model of the intersection, your job is to use synchronization primitives to implement a solution meeting the following requirements:
-
No two cars may be in the same quadrant of the intersection at the same time. This constitutes a crash.
-
Once a car enters any intersection quadrant it must always be in some quadrant until it calls
leaveIntersection. -
Cars do not move diagonally between intersection quadrants.
-
Your solution should improve traffic flow compared to a conventional four-way stop while not starving traffic from any direction.
-
Also don’t hit the dog!
6.2.1. Stoplight code reading questions
Before you begin coding, consider the following questions:
-
Assume that Buffalonians are not Buffalonians and obey the law: whoever arrives at the intersection first proceeds first. Using the language of synchronization primitives describe the way this intersection is controlled. In what ways is this method suboptimal?
-
Now, assume that the Buffalonians are Buffalonians and do not follow the convention described above. In what one instance can this four-‐‑way-‐‑stop intersection produce a deadlock? It is helpful to think of this in terms of the model we are using instead of trying to visualize an actual intersection.
We have provided driver code for the stoplight problem in stoplight.c. The
driver forks off a number of cars which approach the intersection from a
randomly chosen direction and then randomly call one of three routines:
gostraight, turnleft and turnright. Each car should identify itself as
it passed through any intersection quadrant by calling the inQuadrant
function provided in synchprobs.c, and should identify itself when it
leaves the intersection by calling leaveIntersection.
7. Grading
We will test five things about your ASST1 submission:
-
Do your locks work? We will use
lt{1,2,3}to test this. Most of the points will be forlt1, since the other tests are fairly simple. -
Do your CVs work? We will use
cvt{1,2,3,4}to test this. Most of the points will be forcvt{1,2}, since the other tests are again fairly simple. -
Do your reader-writer locks work? We will use
rwt{1,2,3,4,5}from our test suite to test this. You should implement your own test for your reader-writer locks. -
Does your whale mating solution work? We will use
sp1to test this. -
Does your stoplight solution work? We will use
sp2to test this.
Note that for our testing tools to work you must preserve these menu command mappings so that the tests above work as expected.
7.1. Reader-Writer Lock Tests
Here is a brief description of each of the five tests we will use to evaluate your reader-writer lock implementation:
-
rwt1: An end-to-end test that determines whether your reader-writer locks provide proper mutual exclusion for writers and shared access for readers. You will fail this test if you reader-writer locks do not provide enough read concurrency (as if they were normal locks) or starve readers or writers. -
rwt2: This test determines whether a group of readers can achieve maximum concurrency when using your reader-writer lock. -
rwt{3,4,5}: These are correctness tests similar tolt{2,3}andcvt{3,4}. They panic on success.
Note that, unlike the lock tests, our reader-writer lock tests do not require
you to track ownership: that is, if a thread tries to release a reader-writer
lock that it does not hold that does not have to immediately panic. That
said, it is possible and a good idea to do this both for readers and writers:
take a look at kern/include/array.h for some help. We just don’t test it.